
DeepSeek 还能这么玩? 我用它修仙、宫斗、末日求生,太上头了
DeepSeek 还能这么玩? 我用它修仙、宫斗、末日求生,太上头了前几天元旦,DeepSeek 又激发了「假期更新」 Buff,梁文锋署名新论文刷屏 AI 圈,就在大家都在等待 V4 的发布时,我发现有一群人早就在 DeepSeek 里找到了新乐子:自制「橙光游戏」。
来自主题: AI资讯
10453 点击 2026-01-11 10:04
 搜索
搜索
前几天元旦,DeepSeek 又激发了「假期更新」 Buff,梁文锋署名新论文刷屏 AI 圈,就在大家都在等待 V4 的发布时,我发现有一群人早就在 DeepSeek 里找到了新乐子:自制「橙光游戏」。

最近,APPSO 终于拿到了这台来自黄仁勋倾情推荐的个人超算,英伟达 DGX Spark;到手的第一感觉,就是「小而美」。这电脑也太小了,没有 Mac Studio 那般笨重,可能就和 Mac Mini 差不多大;然后是银色的亮和用来散热的金属丝网又让它有点不一样,是专属的硬核美感。

回顾 2025 年,如果问普通人对 AI 行业最深刻的印象是什么?答案依然是激烈的“参数战争”:有 DeepSeek、Gemini 3 等大模型的集体爆发,也有文生图、文生视频能力的持续惊艳。

这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。
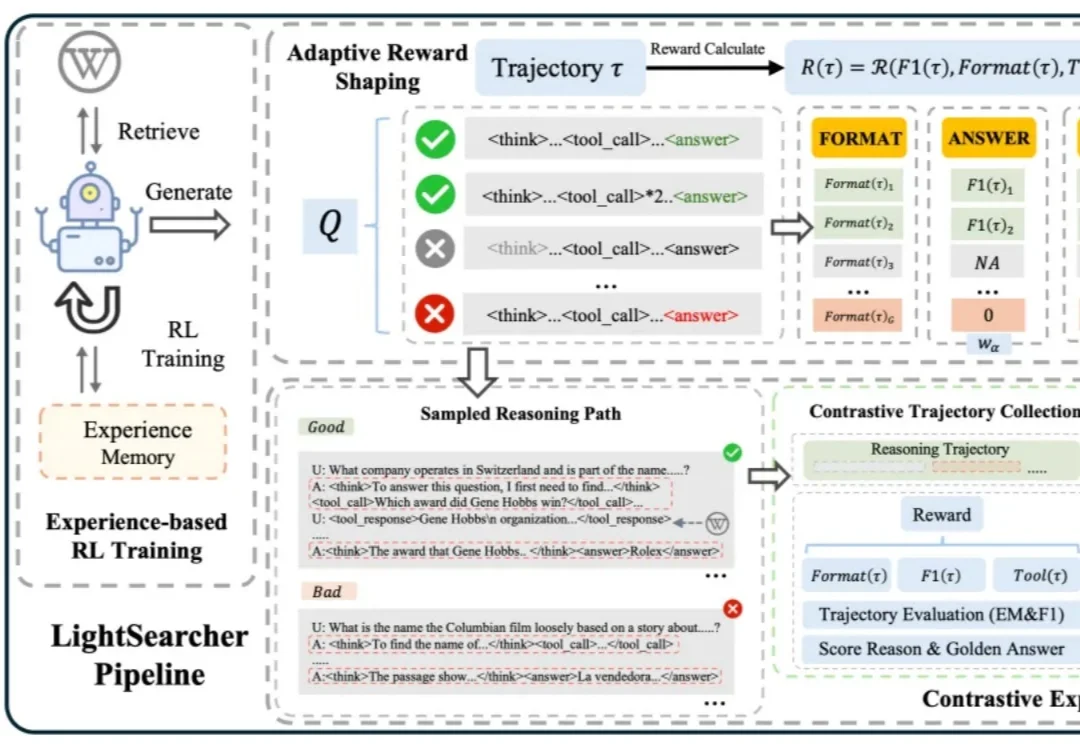
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。

开源模型再次迎来一位重磅选手,就在刚刚,小米正式发布并开源新模型 MiMo-V2-Flash。
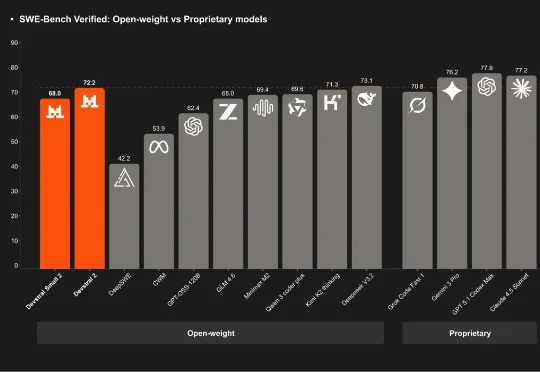
刚刚,「欧洲的 DeepSeek」Mistral AI 再次开源,发布了其下一代代码模型系列:Devstral 2。该系列开源模型包含两个尺寸:Devstral 2 (123B) 和 Devstral Small 2 (24B)。用户目前也可通过官方的 API 免费使用它们。

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。
就在前天,DeepSeek 一口气上新了两个新模型,DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。

刚刚,「欧洲的 DeepSeek」Mistral AI 刚刚发布了新一代的开放模型 Mistral 3 系列模型。该系列有多个模型,具体包括:「世界上最好的小型模型」:Ministral 3(14B、8B、3B),每个模型都发布了基础版、指令微调版和推理版。